Searching text corpora in Tibetan Unicode
This post introduces two free applications that we recently tested for searching through the Tibetan Unicode text corpora that have kindly been made available by "ACIP":https://asianclassics.org/library/downloads/, "BDRC zenodo":https://zenodo.org/record/821218#.Xu5IOOdYxld, "BDRC OpenPecha":https://github.com/OpenPecha/openpecha-catalog, "Esukhia":https://github.com/Esukhia/Corpora, "buddhism.ru":https://bit.ly/3fJ0u93 and others. Each application has its own advantages and shortcomings as regards usability and performance, also they return different search results.
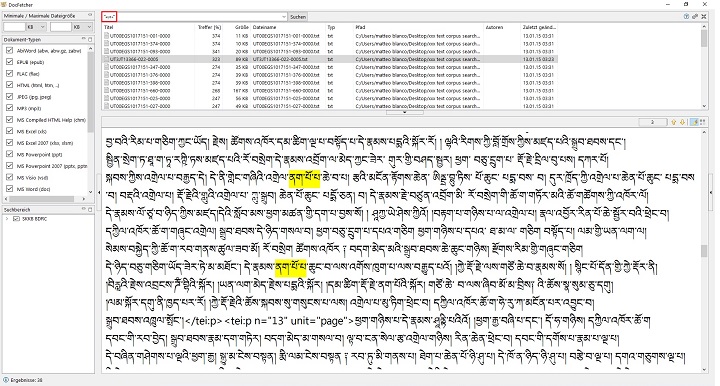
1) "Docfetcher":http://docfetcher.sourceforge.net/en/index.html (accessed: 2020-06-20)
- desktop search application for Windows, Linux and OS X (open source)
- supports txt files and many other document formats, but no xml (those files need to be renamed into txt files before creating the index)
- index-based search
- search in "quotation marks"
2) "AntConc":https://www.laurenceanthony.net/software/antconc/ (accessed: 2020-06-20)
- corpus analysis toolkit for concordancing and text analysis for Windows, Linux and OS X (freeware)
- supports txt, html and xml files (hide tags-function)
- searches files live (performance slow, crashes frequently on macOS Catalina)
- particular settings for proper Tibetan display (font and font size) and search in Tibetan required; see "Esukhia, GitHub":https://github.com/Esukhia/Corpora/tree/master/Nanhai
- direct Tibetan input (searchbar) does not work under Windows 10 (copy paste search phrase)
p=. !https://sakyaresearch.org/system/SRC-I804/62026da000f6566c7fc9e3c2ca56104f.jpg(AntConc, "ནག་པོ་པ")!
{kind=link}